要说这个数据库事务啊,讲究的是 ACID。在分布式场景下,这四个没有一个是简单的,今天我们的话题主要涉及到 A(tomic)。
一、分布式环境的复杂性
在单机环境下,实现事务原子性并不复杂。一般的做法是事务提交之前的写入被存放在 预写式日志 中,然后在事务提交时,往磁盘追加一条 提交记录,完成事务的提交。
所谓 Commit Point,在这个场景下指的是 提交记录 被持久化到磁盘的一瞬间。在此之前,整个事务的写入都是未生效的状态,事务提交可能被回滚或中止(即使客户端已经发送了 Commit 命令,数据库可能在 Commit Point 之前崩溃);而在 Commit Point 之后,整个事务就被提交成功了(即使由于数据库崩溃没来得及把结果返回给客户端)。
本质上,Commit Point 通过把事务内的多条 SQL 语句或者说多个对象的更新是否被提交“归约”到一个单点,也就是事务的 提交记录,从而确保了“要么同时提交,要么同时回滚”。
在分布式事务中,一个事务会同时牵扯到多个节点。这可能是因为事务本身要更新保存在不同节点的多个对象,也可能因为数据和索引保存在不同的节点(Global Index)。如果沿用单机数据库的经验,通过存储引擎中的 提交记录 来照葫芦画瓢,很容易出现原子性被破坏的情况:
- 部分节点成功提交,而部分节点由于冲突等原因需要回滚
- 部分节点成功提交,部分节点由于网络中断或崩溃无法提交
- 客户端与部分节点网络中断
- 客户端在向部分节点发送请求后崩溃
二、两阶段提交
两阶段提交(2PC)引入了 协调者(coordinator) 的角色,它通常以库的形式嵌入在发起事务的进程中,也可以以单独的进程或服务存在——这种情况下通常被称为 事务管理器(transaction manager)。同时我们把持有数据的存储节点称为 参与者(participant)。
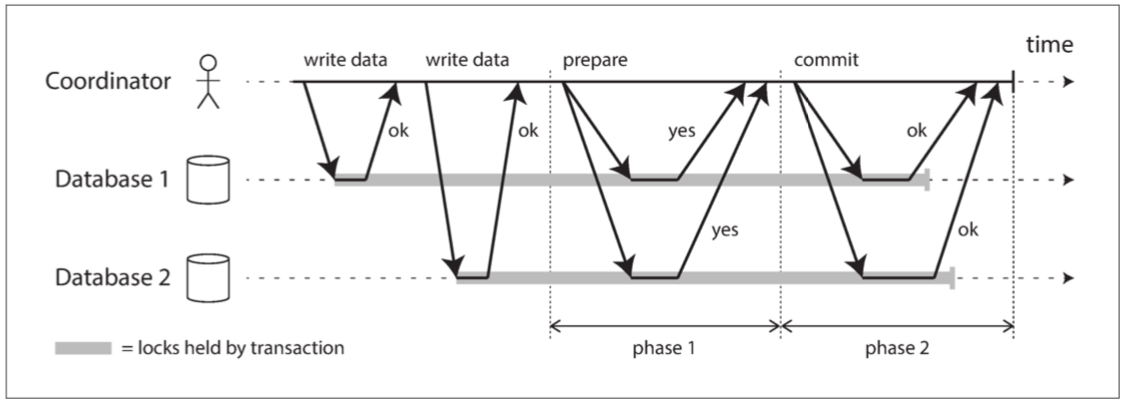
两阶段提交(来源:设计数据密集型应用)
所谓两阶段,是 协调者 在提交的过程中,分两个步骤分别与 参与者 交互:
- 发送 准备(prepare) 请求给所有 参与者 ,询问是否可能提交。
- 如果所有 参与者 都回复
YES,则发起第 2 阶段的 提交(commit) 真正提交;如果任意一个 参与者 回复NO或者超时无响应,则第 2 阶段改为 中止(abort) 回滚之前的操作。
这个过程类似西方婚礼时的流程。神父在第一阶段询问新娘和新郎是否要结婚,如果新娘和新郎都回复YES,神父才进入第二阶段,宣布二人结为夫妻。如果任意一个人说NO,结婚就中止了。
很显然,这个流程能防止“部分节点由于冲突等原因需要回滚”,但是并不能防住由于崩溃或者网络中断导致的不同步。好比神父在宣布二人结为夫妻时,新郎由于心情激动晕倒了没有听到,他醒来以后结婚还是未完成的状态,原子性就这样被破坏了。
解决这种“不同步”的关键正是 Commit Point,正如前面所说,我们需要把多个对象的更新归约到一个单点。实践中,Commit Point 可以有多种选择,下面我们来逐一分析:
方案一:协调者 写入 提交记录 时为 Commit Point
这是很自然的想法:既然事务的的流程由单一的 协调者 控制的,那么直接把单机的 提交记录 引入 协调者 就可以了。协调者 在发起第二阶段 提交 之前,先在本地记录一份 提交记录,提交记录 被持久化标志着整个事务提交成功,即 Commit Point。
对于 参与者 来说,当其在第一阶段回复YES后,就进入了 存疑(uncertain) 状态,直到收到 协调者 发来的第二阶段请求。在 存疑 状态时,整个事务可能提交了也可能没有提交(由 Commit Point 决定),也有可能事务已经被 abort。
回到婚礼的情景。这个方法就相当于神父在宣布结果之前,先记在一个小本本上,新娘新郎有没有结婚成功,完全以小本本上的记录为准。这个过程中不管是新人一方晕倒了或者是神父晕倒了,甚至大家全都晕倒了,只要小本本还在,所有人都能达成一致意见。
X/Open XA 事务 就是采用的这种方式。这个方案依赖于可靠的 协调者,需要保证即使发生崩溃也要能恢复服务并且不丢失数据,因此往往会做成独立的高可用的 事务管理器 服务,形成集群的单点。
方案二:所有 参与者 完成第一阶段时为 Commit Point
这是一个“去中心化”的思路,想法是这样的:在依赖 协调者 写 提交记录 的方案中,当所有 参与者 都回复YES后,只要 协调者 不出意外,总是会写入提交成功的记录,因此 Commit Point 可以往前推,变成“所有 参与者 都回复YES”。
在婚礼的例子里,这个方法就是说结婚成功与否并不取决于神父或者神父的小本本,而是由新娘新郎是否都回答了 YES 唯一决定。只要两人都记得当时自己回答了什么并且不撒谎,不管婚礼现场发生了什么意外,事后大家把两人找出来重新问一下就可以了。
据不可靠消息 OceanBase 采用的正是这种方式。此方案的优点是延迟最小,因为不需要等待 协调者 持久化 提交记录 ,但是当发生异常时恢复成本比较高,因为需要询问所有的 参与者。另一个设计上的关键点在于由谁来维护事务的 参与者 列表:如果由 协调者 来负责,与前一种方案类似,必须要确保 协调者 的可靠性;也可以把列表在第一阶段同步给所有的 参与者,这时付出的代价是增加了 参与者 要持久化的数据量。
方案三:某一特殊 参与者 完成第二阶段时为 Commit Point
最后一种方法是从 参与者 中选出一个来作为 Primary,在提交的第二阶段 协调者 会先把请求发给 Primary,以 Primary 提交成功作为整个事务的 Commit Point。相比于第一个方案,这个方法也有“去中心化”的效果,不过 Commit Point 往后推迟了。
还是回到婚礼。婚礼之前,大家商量好了结果以新娘(Primary)是否收到神父的宣告为准,如果出现任何异常,只要新郎记得 Primary 是新娘,到时候直接去问新娘就行。
TiDB 采用的就是这个方式。这个方案的优点是去中心化,不需要考虑 协调者 的可靠性,而且带给 参与者 的附带成本较低(只用记录 Primary 而不是所有 参与者 )。缺点就是延迟在三个方案中是最高的。
三、处理 存疑 状态
最后我们讨论 2 个关于 存疑 状态的小问题。
1. 恢复中断的事务
如前所述,当 参与者 回复第一阶段消息后就进入 存疑 状态,直到收到第二阶段的消息为止。在此期间由于无法知道事务提交成功还是失败,事务涉及的数据会进入 block 状态无法响应读写。因此不论 Commit Point 如何选择,都必须要考虑中断的事务怎么恢复。
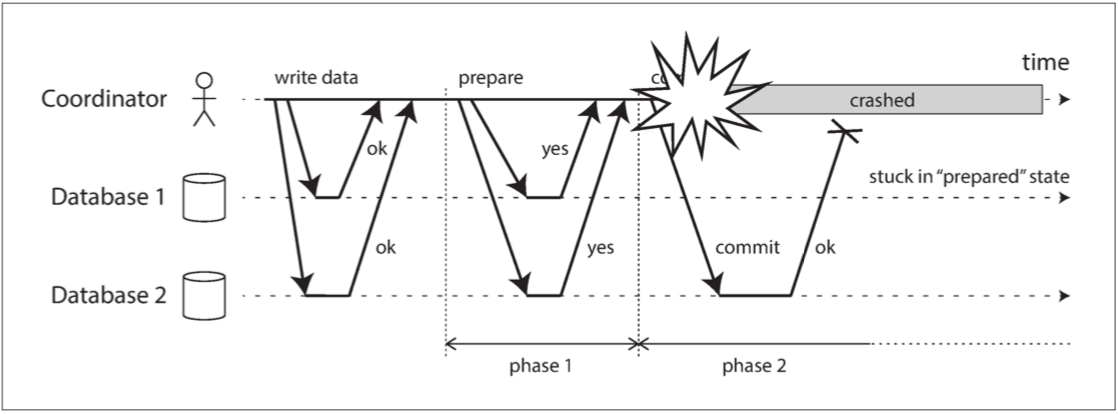
协调者崩溃(来源:设计数据密集型应用)
对于方案 1,因为事务的 提交记录 和 参与者 列表都在 协调者 持久化了,很显然应该由 协调者 在恢复后负责恢复。具体地,如果已经写入 提交记录 了,那么应该向所有 参与者 发送 Commit 消息;反之说明还没有过 Commit Point,此时可以选择直接 abort 事务,如果 协调者 保存了完整的事务信息,也可以重新从第一阶段开始两阶段提交,不过要注意这么做需要 参与者 支持接收重复的 准备 请求(幂等性)。
再看方案 3。由于 协调者 不持久化任何事务状态,中断事务的恢复应该由 参与者 负责。简单地说,处于 存疑 状态的 参与者 可以通过查询 Primary 来获知事务的状态来决定把自身的 存疑 调整为 已提交 或者 已中止。TiDB 中,中断事务的恢复是惰性的 ,参与者 不会主动推进事务,而是当有新事务访问到 存疑 状态的数据时,新事务的 协调者 客串一下原事务的 协调者 来进行恢复。
至于方案 2 就比较灵活了,既可以使用方案 1 的方式也可以使用方案 3 的方式,取决于 参与者 列表是保存在 协调者 还是 参与者。
2. 应该如何回复客户端
这个是在 TiDB 的开发中遇到的,仅以 TiDB 为例说明,其他的方案应该也会存在类似的问题。
在 TiDB 的事务模型里,tidb-server 和 tikv-server 分别扮演 协调者 和 参与者 ,当 tidb-server 发出 CommitPrimary 请求之后就进入了 存疑 状态,此时如果 tikv-server 崩溃或者与 tidb-server 网络断开,tidb-server 就无从得知事务是否提交了。
这种情况下,tidb-server 既不能给客户端返回成功(可能 CommitPrimary 并没有被 tikv-server 收到),也不能给客户端返回错误(可能已经过了 Commit Point,但客户端会误认为事务失败)。此时只有两种办法,要么什么也不做等客户端自行超时,要么直接断开客户端的连接。TiDB 的做法是在一段时间内不断重试,寄希望于能恢复与 tikv-server 的连接,如果经过长时间重试仍然无法解除 存疑 状态,最后就会直接断开连接来把 存疑 的状态给传导给客户端。
值得注意的是,客户端需要处理事务的 存疑 状态,这并不是分布式数据库所特有的问题。即使是单机的 MySQL,也存在“客户端发送 Commit 命令的一瞬间网络断开”的可能,此时客户端同样无从判断服务端的情况从而进入 存疑 状态。
参考: