全面使用 UTF-8
宣言
本文愿景
为了推广 UTF-8 编码的使用和支持,为了使人们相信不论存储在内存还是磁盘,还是通信或所有其他场合,UTF-8 都应当是文本串编码的默认选择。我们相信所有其他的 Unicode 编码(或广义上的文本编码)都属于特殊条件下有针对性的优化,应当避免被主流用户使用。
本文档包含特殊字符。如果没有良好的渲染支持,你可能会看到问号、方框或其他符号。
特别地,我们相信非常流行的 UTF-16 编码(Windows 世界中被误用为 'widechar' 和 'Unicode' 的同义词)不应当出现在库 API 中(除了库是专用于处理文本的特殊情况)。
本文档建议在 Windows 应用程序中选择 UTF-8 存储字符串,虽然 Windows 平台由于历史的原因 API 缺乏对 UTF-8 的原生支持,导致 UTF-8 使用不广。但是我们相信即使在 Windows 平台,下文将要谈到的因素超越了原生支持不足。同样,我们推荐永远忘掉“ANSI 代码页”的存在。用户应当有权在任意文本中混合任意多种不同的语言。
我们建议 C++ 应用程序避免依赖于 UNICODE 或 _UNICODE 宏定义。其中包括依赖于 TCHAR/LPTSTR 的以宏定义的 Windows API,例如 CreateWindow 和 _tcslen。我们会给出使用这些 API 的一些方案。
我们同样相信,如果一个应用程序不是专门用于处理文件的,基础设施有义务保证编写该应用程序时不需要考虑编码问题。例如,一个文件拷贝工具不应为了支持非英文的文件名而使用不同的写法。Joel 关于 Unicode 的经典文章很好的向新手说明了编码,但它遗漏了最重要的部分:在程序员不关心字符串内部是什么的前提下应该怎么做。
背景
1988 年,Joseph D. Becker 发表了第一个 Unicode 草案。他最初的设计天真地认为每字符使用16字节就够用了。1991 年,代码点限制为 16 位的 Unicode 标准第一版发布。它在接下来的数年中吸引许多系统添加了对 Unicode 的支持并迁移到 UCS-2 编码,特别是当时的新技术,包括 Qt 框架(1992)、Windows NT 3.1(1993)及 Java(1995)。
然而,人们很快发现 Unicode 每字符使用 16 位是不够的。1996 年,为了使已有系统支持非 16 位字符,UTF-16 被发明了出来。很快人们就废止了最初选择 16 位字符的合理性,即选择等宽编码的合理性。现在 Unicode 已扩充至 109449 字符,包括 74500 个 CJK 表意字符。

微软一直以来将 'Unicode' 和'宽字符'误用为 'UCS-2' 和 'UTF-16' 的同义词。更进一步,由于窄字符 WinAPI 不接收 UTF-8 编码,代码必须使用宏 UNICODE 进行编译。Windows C++ 程序员被教育成 Unicode 必须通过'宽字符'来实现,成为了对如何正确处理文本最感困惑的一群人。
与此同时,在 Linux 和 Web 领域出现了一个默认的共识:UTF-8 是地球上最正确的 Unicode 编码。即使它相对于其他文本对英语更友好,同样也对计算机语言(如 C++、HTML、XML 等)更友好。它在处理常用字符集时很少会比 UTF-16 低效。
事实
- 不论是 UTF-8 还是 UTF-16 编码,代码点都可能需要长达 4 个字节。(根据 Joel 所说的)。
- UTF-8 与字节序无关。而 UTF-16 有两个版本:UTF-16LE 和 UTF-16BE(分别针对不同的字节序)。这里我们将它们统称为 UTF-16。
- 宽字符在某些平台上是 2 字节,某些平台上是 4 字节。
- 按字典排序时,UTF-8 和 UTF-32 结果相同。而 UTF-16 与它们不同。
- UTF-8 能更高效地处理英文字母及其它 ASCII 字符(每字符使用单字节),UTF-16 能更高效地处理某些亚洲字符集(2 字节而不是 UTF-8 的 3 字节)。这是 UTF-8 成为 Web 领域最佳选择的原因:这些领域使用英文的 HTML/XML 标记来混合其他语言的文本。Cyrillic、Hebrew 和其它一些流行的 Unicode 区段在 UTF-16 和 UTF-8 中都为 2 字节。
- 在 Linux 领域,几乎所有的地方窄字符都被认为是 UTF-8。这样,例如文件拷贝工具就不需要关心编码了。一旦测试了使用 ASCII 字符串作为文件名参数,它就一定能正确处理任意语言的文件名,参数被当作不透明的数据类型来处理,
argv也是一样的。 - 然而在微软 Windows 上,创建一个能接收混合了不同 Unicode 区段文件名的文件拷贝程序需要一些高级技巧。首先应用程序必须被编译成可感知 Unicode 的。这种情况下,
main()函数不能接收标准C参数,只能接收 UTF-16 编码的argv。为了把一个使用窄字符写就的 Windows 程序转为支持 Unicode,必须要进行深入重构并小心处理每一个字符串变量。 - Windows 中,
HKLM\SYSTEM\CurrentControlSet\Control\Nls\CodePage\ACP注册表项可开启接收非 ASCII 字符,但仅限于单个 ASCII 代码页。需使用一个未实现的值 65001 来实现上述功能。 -
MSVC 附带的标准库并不是一份良好实现。它直接将窄字符参数转发至操作系统 ANSI API。没有办法覆写这个特性。更改
std::locale也没用。MSVC 中不可能使用标准C++方法来打开文件名包含 Unicode 字符的文件。C++ 打开文件的标准方法是:
正确的方式是用微软提供非标准扩展,使用微软自己提供的特殊处理来使其接收宽字符参数。std::fstream fout("abc.txt"); - 除了使用 UTF-8,没有其它方法能在
std::exception::what()中返回 Unicode。 - UTF-16 常常被误用为等宽编码,甚至被 Windows 原生程序误用:在 Windows 文本编辑控件中(一直到 Vista),需要 2 次退格才能删除占 4 字节的 UTF-16 字符。在 Windows 7 中,控制台将 4 字节的 UTF-16 字符显示为 2 个无效字符,不论使用何种字体。
- 许多 Windows 平台的第三方库不支持 Unicode:他们只接收窄字符参数并传递给 ANSI API,有时甚至对于文件名也是如此。通常情况下不可能绕过这个问题,因为有些字符串无法被任何 ANSI 完全表示(如果它包含的字符来自多个 Unicode 区段)。Windows 中处理文件名的常用方法是获取文件的 8.3 短路径(如果文件已经存在)后传递给这样的库。如果库试图去创建不存在的文件,这个方法就没用了。如果路径很长,8.3 短路径的长度大于
MAX_PATH,这个方法也没用了。如果短路径生成被操作系统设置禁止,这个方法也没用了。 - 如今 UTF-16 特别流行,不限于 Windows 世界。Qt、Java、C#、Python(CPython v3.3 之前的实现,参考下文)以及 ICU —— 它们都使用 UTF-16 作为内部字符串的存储形式。
我们的结论
UTF-16 使用变宽字符而且占用过多字节,表现最糟糕。它的存在是历史原因造成的,引起了很多混乱,应该被终结。
可移植性,跨平台兼容和简洁比跨平台 API 兼容更重要。所以,最佳途径是总是使用 UTF-8,并在调用接收字符串的 Windows API 前后进行转换。处理字符串相关的系统 API(例如 UI 代码及文件系统 API)时性能很少成为问题。与之相对所有地方总是使用统一的编码好处是巨大的,而且我们认为没有足够的理由不这样做。
说到性能,计算机通常使用字符串通信(如 HTTP 头、XML)。许多人认为这是一个错误,这点暂且不谈。这些场合下几乎都使用英语,给 UTF-8 提供了更大的优势。为不同类型的字符串使用不同的编码将显著增加复杂性和随之而来的 bug。
特别地,我们相信 C++ 中添加 wchar_t 是个错误,C++11 中引入 Unicode 也一样。实现者须保证任何基础字符处理集都能兼容地存储任何 Unicode 数据。于是,每个 std::string 或 char* 参数都必须是 Unicode 兼容的。“如果接受文本,就应当兼容 Unicode” —— 使用 UTF-8 也很容易做到这点。
facets 标准有很多设计漏洞。其中包括 std::numpunct、std::moneypunct 和 std::ctype 都不支持变宽的字符编码(非ASCII UTF-8 和 非 BMP UTF-16),它们只支持等宽字符:
decimal_point()和thousands_sep()应当返回字符串而不是单个代码单元。(顺便提一下,C locale 支持这一点,虽然不是定制的。)toupper()和tolower()不应以代码单元的方式表示,因为它们在 Unicode 下无法工作。例如拉丁文中的连词 ffl 须转为 FFL、德文中的 ß 须转为 SS(ẞ 有大写形式,但大小写规则遵循传统形式)。
Windows 上如何处理文本
以下是我们推荐给所有人的建议,除了编译期 Unicode 正确性检查,还提供了更佳的易用性和更好的平台无关代码。这大大不同于通常所建议的 Windows 平台使用 Unicode 的正确方式。然而,针对这些建议的深入研究得出了相同的结论。让我们来看看:
- 除了与 UTF-16 API 的临界点,任何地方都不要使用
wchar_t或std::wstring。 - 除了传给 UTF-16 API 的参数,任何地方都不要使用
_T("")或L""。 - 不要使用与
UNICODE常量相关的类型、函数或其衍生设施,例如LPTSTR或CreateWindow()。 - 但总是保留
UNICODE和_UNICODE定义,以避免窄字符串被误传给 WinAPI 通过编译。 - 程序中出现的所有
std::strings和char*都认为是 UTF-8(如果不被明确指示为其他编码)。 -
只使用接收宽字符(
LPWSTR)的 Win32 函数,永远不使用接受LPTSTR或LPSTR的。以如下方式传递参数:
(此策略使用了下文所述的转换函数。)::SetWindowTextW(widen(someStdString or "string litteral").c_str()) -
对于 MFC 字符串:
CString someoneElse; // something that arrived from MFC. // Converted as soon as possible, before passing any further away from the API call: std::string s = str(boost::format("Hello %s\n") % narrow(someoneElse)); AfxMessageBox(widen(s).c_str(), L"Error", MB_OK);
处理 Windows 平台的文件、文件件名和文件流
- 永远不输出非 UTF-8 编码的文本文件。
- 因 RAII/OOD 的原因应避免使用
fopen()。如果有必要,使用_wfopen()并用上文所述的 WinAPI 转换方法。 - 永远不要向
fstream系列组件传递std::string或const char*文件名参数。MSVC CRT 不支持 UTF-8 参数,但它有一个非标准的扩展,使用方式如下: -
使用
widen将std::string参数转为std::wstring:
若 MSVC 对std::ifstream ifs(widen("hello"), std::ios_base::binary);fstream的方针变化,我们将手动删除这个转换。 - 这份代码不适用于多平台,可能会在未来被修改。
- 还可以使用一系列封装来隐藏这些转换。
转换函数
这份指引使用来自 Boost.Nowide 库 的转换函数(目前还不是 boost 的一部分):
std::string narrow(const wchar_t *s);
std::wstring widen(const char *s);
std::string narrow(const std::wstring &s);
std::wstring widen(const std::string &s);这个库还提供了一系列处理文件的常用 C 和 C++ 函数封装,以及通过 IO 流读写 UTF-8 的手段。
这些函数和封装可以用 Windows 的 MultiByteToWideChar and WideCharToMultiByte 轻易实现。也可以使用任何其他(可能更快)转换例程。
FAQ
-
Q: 你是 Linux 信徒吗?这是针对 Windows 的隐蔽宗教战争吗?
A: 不,我在 Windows 下成长,而且我是 Windows 粉。我相信他们在文本领域做出了错误选择,因为他们比其他人做的要早。—— Pavel
-
Q: 你是亲英主义者吗?你是否暗暗觉得英语字母和文化要优于其它?
A: 不是,而且我的国家使用非 ACSII 语言。我认为使用一种将 ASCII 字符编码进单个字节的格式谈不上主义,也与人类问题没有关系。虽然我们可以争论程序源代码、网页、XML 文件、操作系统文件名及其它计算机文本界面等文本不应该存在,但只要它们存在,人类就不是文本的唯一用户。
-
Q: 你们为什么在意这些呢?我是 C# 和/或 Java 程序员,从来不用关心编码。
A: 并非如此。C# 和 Java 都提供 16 位
char类型,是小于 Unicode 字符的,恭喜。.NET 使用字符串的内部表示为单位来索引str[i],这是有遗漏的抽象。取子串的方法会很愉快地将非 BMP 字符切开并返回非法字符串。而且在写文本至磁盘文件、网络通信、外部设备或任何其他程序会读取的地方时,你都必须考虑编码。这些情况下请考虑使用
或手机 PDU。System.Text.Encoding.UTF8(.NET),而不是对文本内容做出假设后使用Encoding.ASCII、UTF-16以 ASP.NET 为代表的 Web 框架就因其所依赖框架在字符串内部表示的糟糕选择而深受其害:Web 程序期望的字符串输出(和输入)几乎总是 UTF-8,导致了高负载的 Web 应用和 Web 服务上显著的转换开销。
-
Q: 为什么不让程序员任意使用他喜欢的编码,只要他知道怎么使用?
A: 我们不反对正确地使用任意编码。但是,当某些类型,如
std::string,在不同上下文中代表不同的东西,这就成了问题。有些时候代表 'ANSI 代码页',有些时候代表 '代码问题,只支持英文文本'。在我们的程序中,总是代表 '可适应 Unicode 的 UTF-8 字符串'。这种多样性是许多 bug 和痛苦的源头:徒增的复杂性不是我们真正需要的,其结果是整个行业大量的不兼容 Unicode 软件。 -
Q: UTF-16 字符占用多于 2 字节的情形在现实世界中并不常见。而 UTF-16 的等宽特性在现实中大有优势。我们不能直接无视这些字符吗?
A: 关于你的软件设计成不支持全部的 Unicode 这点你是认真的吗?而且,假如你最终还是要支持,而事实是非 BMP 字符几乎不会改变任何事情,除了使软件测试更难?真正重要的是,实践中字符串操作相对稀少 —— 相对于直接传递字符串。这意味着“几乎等宽”只会带来较小的性能优势(参见“性能”),而更短的字符串影响更大。
-
Q: 为什么你要打开
UNICODE定义呢,既然你不准备使用 Windows 的LPTSTR/TCHAR/其他宏定义?A: 这是为了预防 UTF-8 字符串被传递给期待 ANSI 的 Windows API 函数。你希望这种情况下产生编译错误。这跟 Windows 平台上传递
argv[]字符串给fopen()是同一类难以发现的 bug:它假定用户永远不会传递非当前代码页的文件名。你一定不会想手动测试这类 bug,除非你的测试人员被训练为会偶尔试试中文文件名,不管怎样这都是有疏漏的程序逻辑。感谢UNICODE宏定义,这种情况下我们能得到编译错误。 -
Q: 认为微软有一天会停止使用宽字符不是很天真的想法吗?
A: 让我们先来看看他们什么时候开始支持
CP_UTF8合法代码页。这应该不是很难。这样一来,任何人都没有理由继续使用宽字符 API 了。另外,添加CP_UTF8的支持并不会“破坏”一些现有的不支持 Unicode 的程序和库。有人认为添加
CP_UTF8支持会破坏已有的使用 ANSI API 的应用程序,这才是微软求助于发明宽字符 API 的原因。这并非事实。有些流行的 ANSI 编码也是变宽的(如 Shift JIS),所以正确的代码不会被破坏。微软选择 UCS-2 纯粹是历史原因。当时 UTF-8 还不存在,Unicode 被认为是“一种宽字符的 ASCII”,而且使用等宽编码被认为很重要。 -
Q: 什么是字符、代码点、代码单元以及字形集?
A: 以下列出 Unicode 标准中的专业定义及我们的注释。参考标准中的相关章节以获取更详细的说明。
- 代码点
- Unicode 代码空间中的任意数字值。[§3.4, D10]例如:U+3243F。
- 代码单元
- 可表示编码文本的一个单元的最小的二进制位的组合。[§3.9, D77] 例如:UTF-8、UTF-16、UTF32 分别使用 8 位、16 位、32 位代码单元。上述代码点在 UTF-8 中被编码为 ‘
f0 b2 90 bf’,在 UTF-16 中被编码为 ‘d889 dc3f’,在UTF-32中被编码为 ‘0003243f’。注意这些只是一系列的字节分组,它们具体的存储形式依赖于具体编码的字节序。所以,在 16 进制相关媒体上存储上述 UTF-16 代码点时,UTF-16BE 下转为 ‘d8 89 dc 3f’,而 UTF-16LE 下转为 ‘89 d8 3f dc’。 - 抽象字符
-
用于组织、控制、表示文本信息的一个信息单元。[§3.4, D7] 标准 §3.1 中有如下论述:
对于 Unicode 标准,[...] 本质上是开放的。因为 Unicode 是一种通用编码,任何可能被编码的抽象字符都是编码的候选项,不论此字符是否当前为人所知。
这份定义确实抽象。任何能理解成字符的 —— 都是抽象字符。例如,
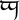 Tengwar 字符 ungwe 就是一个抽象字符,虽然目前并不能被 Unicode 表示。
Tengwar 字符 ungwe 就是一个抽象字符,虽然目前并不能被 Unicode 表示。 - 字符编码
-
代码点与抽象字符间的映射。[§3.4, D11] 例如,U+1F428 是抽象字符 🐨 koala 的字符编码。
这个映射关系既非单射也非满射:
- 非字符的和未被分配的代码点不对应于任何抽象字符。
- 一些抽象字符能被不同代码单元编码。U+03A9 希腊文中的大写字母 omega 和 U+2126 欧姆符号 都对应于相同的抽象字符 ‘Ω’,但必须区分处理。
- 一些抽象字符不能被单个代码单元编码。它们被表示为字符编码的序列。例如,表示抽象字符 ю́ 西里尔语尖音符 yu 的唯一方法是 U+044E 西里尔语小写字母 yu 后接 U+0301 尖音符号 的序列。
甚至有些抽象字符在单个字符编码形式之外还存在多个字符编码的表示形式。抽象字符 ǵ 可被单个字符编码 U+01F5 拉丁小写字母 g 加尖音符编码,也能被 <U+0067 拉丁小写字母 g,U+0301 尖音符> 编码。
- 用户感知字符
- 任何被终端用户认为的字符。这个概念是语言相关的。比如,'ch' 在英文和拉丁文中是两个字母,但在捷克斯洛伐克被认为是单个字母。
- 字形集
- 被认为“应该放置在一起”的字符编码序列。[§2.11] 字形集大致概念是语言无关的用户感知字符。它们用来处理光标移动或选择等。
- 字符
-
可能代表上述的任意一种概念。Unicode 标准中用作 字符编码 的同义词。[§3.4]
当某编程语言或库的文档中说“字符”,几乎总是指代代码单元。当终端用户被询问字符串中字符的个数时,她会计算用户感知字符。当程序员试图计算字符数时,根据其经验层次,可能会计算代码单元、代码点或字形集。所有这些不同的认知是混乱的根源,正如人们会得出这样的结论:如果某个库对字符串 ‘🐨’ 返回的长度大于 1,那么它“不支持 Unicode”。
-
Q: 为什么亚洲用户要放弃 UTF-16 编码,既然它每字符能省 50% 的内存?
A: 只在人工构造的只包含 U+0800 至 U+FFFF 之间的字符的情况下符合这点。但是,现实中计算机通信文本主宰着一切。其中包括 XML、HTTP、文件系统路径和配置文件 —— 它们几乎完全使用 ASCII 字符,而且事实上在这些国家 UTF-8 也经常被使用。
对于中文书籍的存储,使用 UTF-16 或许是一个合理的优化。一旦文本从这样的存储中读出,它就应当被转为与全世界兼容的标准。不管怎样,如果存储代价高昂,也会引入无损压缩。在这种情况下,UTF-8 和 UTF-16 会使用大致相同的空间。此外,“在现存语言中,一个字形符号比一个拉丁符号传达更多的信息,所以它占据更多空间也合情合理。”(Tronic, UTF-16 有害)。
以下是简单试验的结果。第一列是某网页(日文,2012-01-01 从日本维基百科获取)HTML 源文件的空间占用情况。第二列是移除标记后的结果,即“全选、复杂、粘贴进纯文本文件”。
HTML 源代码 (Δ UTF-8) 纯文件 (Δ UTF-8) UTF-8 767 KB (0%) 222 KB (0%) UTF-16 1 186 KB (+55%) 176 KB (−21%) UTF-8 zipped 179 KB (−77%) 83 KB (−63%) UTF-16LE zipped 192 KB (−75%) 76 KB (−66%) UTF-16BE zipped 194 KB (−75%) 77 KB (−65%) 可以看出,真实数据中 UTF-16 比 UTF-8 多占用 50% 的空间,纯亚洲文本的情况只省 20%,很难与通用压缩算法相提并论。
-
Q: 你们对字节序标记(BOM)持什么看法?
A: 依据 Unicode 标准 (v6.2, p.30):
对于 UTF-8,BOM 的使用从未被要求或推荐
。字节序问题是避免使用 UTF-16 的另一个原因。UTF-8 没有字节序的问题,UTF-8 BOM 的存在只是为了表明这是 UTF-8 流。如果 UTF-8 成为唯一流行的编码(在因特网世界中已经是这样),BOM 就是冗余的了。实践中,现在大部分 UTF-8 文本编辑器都忽略 BOM 标记。
-
Q: 你们对换行符持什么看法?
A: 所有文件都是以二进制模式读写的,于是保证了互通性 —— 程序在任何不同系统上都有同样的输出。由于 C/C++ 标准使用
\n作为内存中的换行符,这也就导致了 POSIX 上文件换行符的惯例。这在文件被 Windows 上的 Notepad 打开时可能导致问题;但是,任何得体的文件查看工具应该懂得处理这样的换行符。 -
Q: 那么文本处理算法、字节对齐等相关的性能怎样呢?
A: UTF-16 的性能是不是更好?也许是的。ICU 由于历史原因使用 UTF-16,导致它难于维护。但是,大部分情况下字符串都被用作保存和传递,而不是每次使用时排序或反转。这样尺寸更小的编码对性能更友好。
-
Q: UTF-8 不是为了兼容 ASCII 的吗?为什么还留着这个老古董?
A: 也许是的。但现今,它比其他任何 Unicode 编码都要更好、更流行。
-
Q: 人们误用 UTF-16,认为它是 16 位每字符,是不是 UTF-16 的失败之处?
A: 并不是的。但某种意义上也可以这么认为,安全性是每个设计的重要特性。
-
Q: 如果
std::string表示 UTF-8,难道不会与存储纯文本的std::string发生混淆吗?A: 没有纯文本这种东西。没有理由认为以 'string' 命名的类中存储的应该是 代码页-ANSI 或 ANSI 文本。
-
Q: 传递字符串给 Windows 时 UTF-8 与 UTF-16 间的相互转换不会使我的应用程序变慢吗?
A: 首先,不管怎样你总要做一些转换的。要么是系统调用,要么是与外部做交互。甚至如果你的应用跟系统交互更加频繁,这里有一个小试验。
一个典型的系统调用是打开文件。在我的机器,这个函数执行耗时 (184 ± 3)μs:
void f(const wchar_t* name) { HANDLE f = CreateFile(name, GENERIC_WRITE, FILE_SHARE_READ, 0, CREATE_ALWAYS, 0, 0); DWORD written; WriteFile(f, "Hello world!\n", 13, &written, 0); CloseHandle(f); }而这个函数耗时 (186 ± 0.7)μs:
void f(const char* name) { HANDLE f = CreateFile(widen(name).c_str(), GENERIC_WRITE, FILE_SHARE_READ, 0, CREATE_ALWAYS, 0, 0); DWORD written; WriteFile(f, "Hello world!\n", 13, &written, 0); CloseHandle(f); }(两种情况都使用
name="D:\\a\\test\\subdir\\subsubdir\\this is the sub dir\\a.txt"运行。运行 5 次取平均值。我们使用优化过的widen,依赖于 C++11 所保证的std::string存储于连续内存。)只有 (1 ± 2)% 的差异。而且,几乎可以肯定
MultiByteToWideChar更为高效。还存在性能更好的 UTF-8↔UTF-16 转换。 -
Q: 如果在C++ 源文件中显式地使用 UTF-8 字符串?
A: 如果你的软件是国际化的,那么所有的非 ASCII 字符串都将从外部翻译数据库,所以这将不是个问题。
如果你还是想嵌入特殊字符你可以这么做。C++11 中你可以用如下方法:
u8"∃y ∀x ¬(x ≺ y)"针对不支持 'u8' 的编译器,你可以用如下方法硬编码 UTF-8 代码单元:
"\xE2\x88\x83y \xE2\x88\x80x \xC2\xAC(x \xE2\x89\xBA y)"当然最直接的方式是直接编写字符串并将源文件以 UTF-8 保存:
"∃y ∀x ¬(x ≺ y)"不幸的是,MSVC 会把源文件转到某个 ANSI 代码页,将破坏字符串。针对这个问题,将文件保存为不带 BOM 的 UTF-8。MSVC 会假设其为正确的代码页,不碰你的字符串。但是,它的渲染方式将使你无法使用 Unicode 标识符和宽字符(反正你也不会使用)。
-
Q: 我应该怎么检测特定 ASCII 字符在 UTF-8 字符串中的存在性,例如防止 SQL 注入的单引号('),或 HTML 标签特殊字符等?
A: 和 ASCII 字符串一样处理。所有非 ACSII 字符在 UTF-8 中都被编码为值大于 127 的字节序列。不会与任何简单的算法发生冲突 —— 快速而简捷。
同样的,你可以在 UTF-8 字符串中查询 UTF-8 编码的子串,就如同纯字节数组一样 —— 不必担心代码点边界。这是被 UTF-8 特性所保证的 —— 任何编码后的代码点字节前缀都不会包含任何其他代码点字节的后缀。
-
Q: 我有一个巨大而复杂的基于 char 的 Windows 应用程序。使其变得适应 Unicode 的最简单方法是?
保留 char。定义
UNICODE和_UNICODE,在产生编译错误的地方使用narrow()/widen()(这在 Visual Studio 工程选项中设置使用 Unicode 字符集后会被自动完成)。找出所有使用了fstream和fopen()的地方,使用上文所述的 wide。到这里就差不多完成了。如果你使用了不支持 Unicode 的第三方库,例如把文件名原封不动传给
fopen(),你将需要使用上文所述的工具来解决,如GetShortPathName()。 -
Q: Python 如何?我听说他们为了更好地支持 Unicode 在 v3.3 作出了巨大努力。
A: 也许吧,他们应该做得更少而支持得更好。在 CPython v3.3 的参考实现中,字符串的内部表示发生了改变。针对不同的字符内容,原本的 UTF-16 现在可能是三种编码的其中之一(ISO-8859-1,UCS-2 或 UCS-4)。为了追加单个非 ASCII,非 BMP 字符,整个字符串常常会被转至不同的编码。内部编码对脚本是透明的。这个设计是为了针对 Unicode 代码点优化索引操作的性能。然而,我们对主要使用场景下针对代码点的计数或索引的重要性持怀疑态度 —— 例如与字形集相比。据我们所知,Python 当前并不提供对后者的任何支持。
因此,我们反对表示无关的字符串处理,倾向于提供表示透明的 API 并使用 UTF-8 作内部表示。索引操作应当计算代码单元而不是代码点,正如他们之前的做法。这样在简化实现的基础上还能提升性能,例如 Web 领域已经被 UTF-8 所统治,这样做将使得 Python 编程语言在服务端有更广的应用。可能有人质疑脚本程序员处理字符串分割的安全性,但再一次的,同样的质疑也适用于字形集的分割。虽然现在 Unicode 现在已经被 Python 完全支持,但是我们相信 Python 作为有更少历史包袱的现代工具,必须更好地处理文本。
除此之外,JPython 和 IronPython 持续地依赖于其附属平台(Java 和 .NET)的更加不幸的编码,必须小心地正确处理。
-
Q: 我自己已经使用了这个方案,我希望使我们的愿景变成现实。我能做什么?
A: 审查你的代码,找出在可移植的适应 Unicode 的代码中使用得最痛苦的库。向作者发送 bug 报告。
如果你是某 C/C++ 库作者,使用 UTF-8 编码的
char*和std::string,并拒绝支持 ANSI 代码页 —— 因为它们本质上是 Unicode 不兼容的。如果你是微软雇员,推进将
CP_UTF8实现为支持窄字符 API 的代码页。
流言
注:如果你不熟悉 Unicode 技术,请先阅读此条 FAQ。
注:为了方便讨论,索引字符串也被认为是一种字符计数。
使用 UTF-16 字符计数可以在常数时间内完成。
认为 UTF-16 是等宽编码是一个常见误解。并非如此。事实上 UTF-16 是一种变宽编码。如果你还否认非 BMP 字符的存在,请阅读此条 FAQ。
许多人试着通过切换编码来修复这个判断,有些人提出了下面的判断:
使用 UTF-32 字符计数可以在常数时间内完成。
现在,这个判断是否为真依赖于承载太多不同意义的词“字符”的定义。能使得这个声明正确的释义是“代码单元”或“代码点”,这二者在 UTF-32 中是吻合的。然而,代码点并不是字符,不论是从 Unicode 标准还是终端用户的角度。一些代码点是非字符,故而这二者不能相互置换。所以,假设我们确认字符串中不包含非字符,那么每个代码点将代表一个代码字符,我们就能依赖这点了。
但是,这不是一项重要成就吗?为什么还会有上文中的担心呢?
代码字符或代码点的计数很重要。
代码点的重要性常常被夸大。这是对 Unicode 复杂性的误解导致的,它基本上反映了人类语言的复杂性。分辨 'Abracadabra' 中有多少字符是简单的,但对于以下字符串来说却没那么简单:
Приве́т नमस्ते שָׁלוֹם
上述字符串包含 22(!)个代码点,却只包含 16 个字形集。所以,'Abracadabra' 由 11 个代码点组成,上面的字符串由 22 个代码点组成,转为 NFC 后则进一步变成 20。而代码点的数目几乎无关任何软件工程问题,或许转为 UTF-32 唯一的例外。例如:
- 对于光标移动,文本选择和类似问题,应当使用字形集。
- 对于输入框,文件格式,协议或数据库中字符串长度的长度限制,长度是以预定编码的代码单元来测量的。其原因是任何长度限制都来自于低层次上固定长度的内存分配限制,可能是内存,磁盘或特定的数据结构。
- 字符串在屏幕上的显示尺寸与字符串的代码点数量无关。应该与渲染引擎通信来获取。即使在使用等宽字体的控制台,代码点也不固定占据一列。POSIX 就考虑到了这一点。
另请参见:Twitter 如何计算字符数。
NFC 中每个代码点对应一个用户感知的字符。
否,因为 Unicode 中用户可能感知的字符数几乎是无限大的。即使在实践中,大多数的字符都没有完整的组合形式。以上面例子中字符串的 NFD 形式为例,它由三种真实语言中的三个真实单词组成,在 NFC 中由 20 个代码点组成。依然远大于其含有的 16 个用户感知字符。
字符串的 length() 操作必须计算用户感知字符或代码字符。否则,就不能说它正确支持 Unicode。
库或编程语言对 Unicode 的支持常常被其“字符串长度”操作的返回值来评判。根据这种 Unicode 支持的评判方式,大多数流行的语言,例如 C#、Java 甚至 ICU 本身,都不支持 Unicode。例如,单字符的字符串 ‘🐨’ 在使用 UTF-16 作为内部字符串表示的语言中常常返回 2,在使用 UTF-8 的语言中则返回 4。这种误解的根源是语言规范中“字符”的意思是代码单元,而程序员期待的是别的东西。
关于作者
本宣言由 Pavel Radzivilovsky,Yakov Galka 和 Slava Novgorodov共同写成。这是我们总结自己的经验,调查现实世界中 Unicode 相关问题及现实世界中程序员的常见错误后得出的结果。目的是为了使文本的问题广为人知,鼓舞业界范围的改进,使得适应 Unicode 的编程更简单,最终改善人们写就程序的用户体验。我们几人都未参与 Unicode 协会。特别感谢 Glenn Linderman 提供 Python 相关信息。
本文的许多灵感来自 StackOverflow 上由 Artyom Beilis 发起的讨论,他也是 Boost.Locale 的作者。你可以在那儿留下评论/反馈。另有一些灵感来自 VisionMap 的开发规范,以及 Michael Hartl 的 tauday.org。
外部链接
- Unicode 协会(Unicode 标准,PDF)
- Unicode 国际化组件(ICU)
- Joel 谈 Unicode —— “每个软件开发者必须知道的 Unicode 和 字符集”。
- Boost.Locale —— C++方式的高质量本地化设施。
- UTF-16 应当被认为有害吗? 来自 StackOverflow,由 Artyom Beilis 发起。
- Twitter 如何计算字符数
期待你的帮助和反馈

比特币捐赠至:1UTF8gQmvChQ4MwUHT6XmydjUt9TsuDRn
现金将用于调研和推广。
 |
最后修改:2014-09-30 |